
AI agents represent a transformative leap for generative AI. Unlike traditional systems that merely respond to user inputs, AI agents are capable of autonomously executing complex tasks, reason through problems, and adapt their strategies based on prior experiences and environmental cues.
Enterprise companies have also started to bring their focus on integrating AI agents to enhance employee productivity, particularly in tasks that require processing large volumes of information. These agents can quickly read and analyze numerous sources of data, generate concise summaries that save employees significant time.
At Moveworks, we were excited to apply our agentic AI capabilities to enabling this remarkable shift in employee productivity. That’s why we built Brief Me, a productivity-boosting feature baked into the Moveworks Copilot, enabling employees to upload PDF, Word, and PPT files into chat and interact with the content inside — effectively “talking” to their files. Brief Me also enables employees to strike up a conversation with Copilot and quickly extract the valuable details they care about from lengthy documents.
In this blog, we will talk about how AI agents work inside Brief Me - Moveworks’ personal assistant tool for users to bring in their own data sources in real time and perform complex content generation tasks. These tasks include, but not limited to, summarization, Q&A, comparisons, and gathering insights. We will discuss its agentic architecture, how these enable greater user productivity and delve into the technical details of Brief Me.
What’s the agentic engineering system behind Brief Me?
The agentic framework powering Brief Me is designed to enable Moveworks Copilot users to bring in and summarize information from their own sources of data on the fly. This includes traditional workplace information formats like:
- Documents (ex. PDFs, Docx, PPTs)
- URLs to their own managed files or folders
- Web URLs to externally owned, non-affiliated pages
- Intranet URLs (ex. tickets, Jira links, etc.)
- Additional modalities such as images, audio etc.
From these sources, Brief Me generates real-time content that’s grounded specifically in their source data and files. In our case, content generation can range from simple Q&A style inquiries to complex content generation tasks like summary, analysis, comparison and insight creation. Note that, at the time of publishing, we currently support documents within Brief Me and are planning to expand our support to URLs and other source types.
The versatility of Brief Me’s engineering system enables users to transform and leverage their information into a wide range of applicable uses.
Two-staged briefing agent
Brief Me operations can be grouped into two major operation stages: content ingestion and content generation. Remember, given the density of our discussion, we’re primarily covering only the content generation in today’s blog. However, we’ve offered the following overviews of the operations for orientation purposes.
- Online Source Data Ingestion: Whenever a user brings in their own data, there must be a low latency content ingestion system capable of parsing and processing the information in a format consumable by the agent during content generation.
- Online Content Generation: This stage kicks in once the user is enabled to query their data in a conversational fashion and users are locked into the Brief Me experience. Every query goes through our agentic pipeline which is designed to generate accurate, grounded and verifiable responses.
This blog will focus on Online Content Generation and detail how the system generates authoritative content based on provided sources.
Today’s agentless reality
Imagine you work in sales for a SaaS company. You're swamped with meetings and emails from prospects. A prospect of yours asks how your capabilities compare your offerings to those of your competitors—how do you respond?
Without an AI assistant like Brief Me, the process probably looks something like this:
You start first by manually searching through your available competitive documents to identify the things you want to include
You dig and scan through them to locate the relevant sections of your desired content
Next, you read, process, and develop a viewpoint to position
Lastly, you try and write up a concise response that explains concepts aligned to your advantageous perspective
In a hypothetical situation like this, this level of information synthesis could take hours, especially if you're not expertly versed with the content. This is a simple and commonplace example where Brief Me becomes extremely valuable. The following sections will explain the multi-stage approach used in designing the content generation elements of the agent.
Quick introduction of online ingestion
Once a user uploads files or provides links to sources such as URLs, we initiate an online pipeline to process the provided source data. This ingestion is optimized for real-time operation as soon as the user begins a session. The ingestion pipeline is designed to have a P90 latency of <10 seconds which can help ensure users don't wait too long for their files to be processed.
This stage consists of several sequential processes: First, it fetches the sources. Next, it chunks the files into smaller segments using proprietary techniques. Then, it generates metadata from the sources. Following that, it embeds the chunks. Finally, it performs indexing. These steps—fetching, chunking, metadata generation, embedding, and indexing—form the core of the ingestion pipeline. We will be exploring this source content ingestion stage in more detail in our upcoming blog on this topic.
Locking into Brief Me mode
After the content ingestion pipeline runs successfully, the agent locks users into a focused mode where only the processed sources are available for querying. Every subsequent query gets access to only a certain set of sources which we define as a session. Once the session is closed by the user, the agent gets rid of all the sources for the past session.
Online content generation
Having set the context for previous stages we are ready to dive into the core reasoning engine of our agent responsible to answer user queries.
Components
Getting back to our previous example, the sales rep needs to ask the following question.
Python:
"Write an email detailing how the Moveworks agentic capabilities differ from that of A, B, and C. Keep the email concise and make sure to include details on our new orchestration engine."
We will walk through multiple components of the agent responsible for generating a response to this query.
Query rewriter: Multi-turn capability
While interacting with Brief Me, users might refer to previous turns and responses in their query. The system should incorporate contextual information to enable multi-turn capabilities.
Our approach:
- The Reasoning Engine examines up to n previous turns in the conversation history. It identifies and prioritizes the most relevant turns to generate a new query with full contextual awareness of the chat history.
- We model the interaction history as a series of user-assistant response pairs, with additional metadata injected from each turn based on the reasoning steps. This process helps rewrite the query to accurately represent the context of the conversation.
- We utilize GPT-4o with in-context learning to address this challenge. Additionally, efforts are underway to fine-tune an in-house model trained on synthetic data representative of the types of queries commonly encountered in the enterprise space.
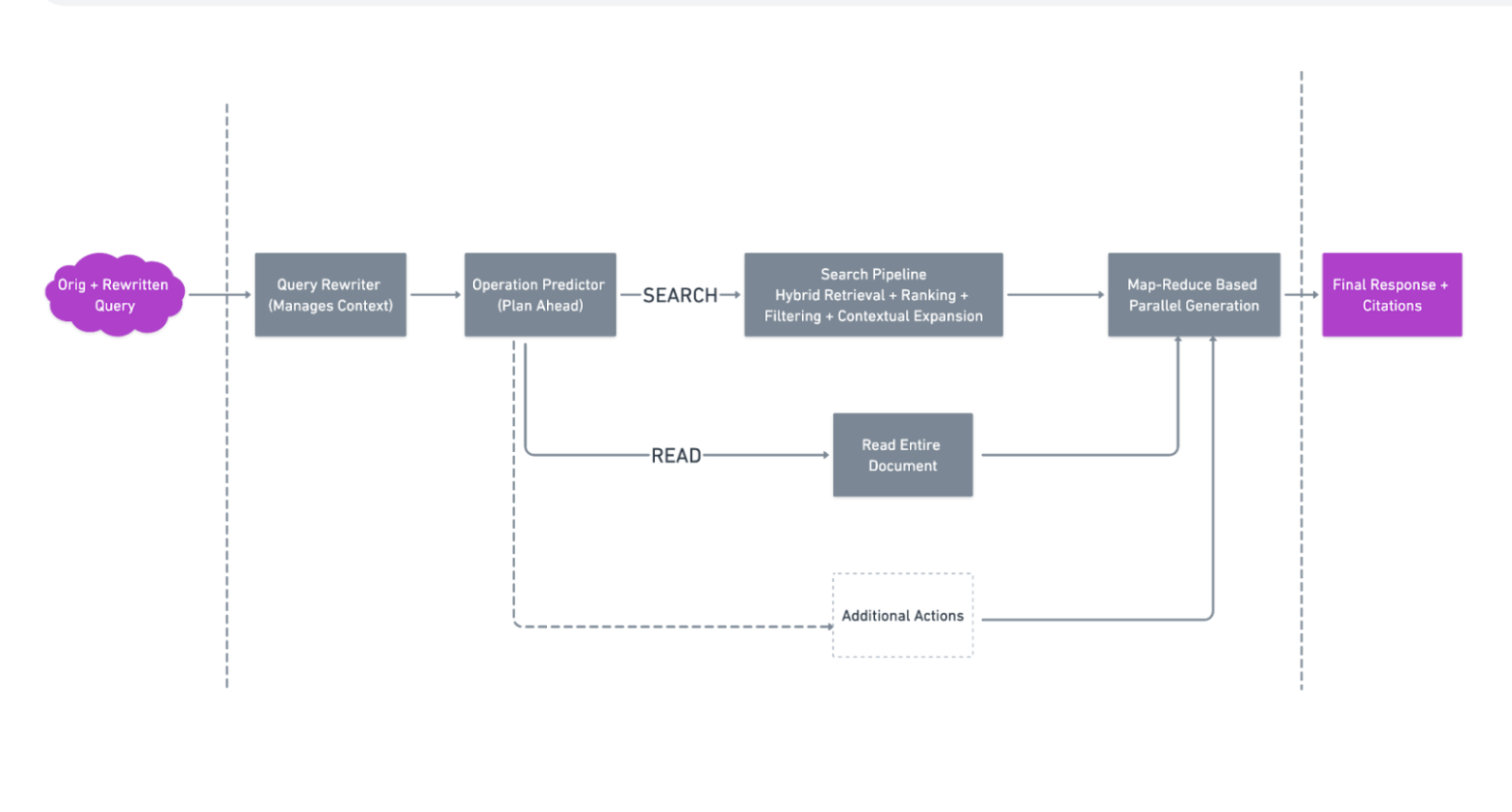
Operation planner
This part of the system forms the crux of how we handle complex and varied kinds of queries inside the agent. This module is the planning step to determine what kind of operations need to be taken over provided sources.
What is an 'operation'?
Each operation is an atomic action to be performed on a set of sources. It is represented by parameters that define how the agent should respond to each action. An action has its own execution path, and the parameters decide what info it can pull from long term memory (provided sources) into the short term memory (memory of the agent).
We will discuss two possible atomic actions at this time. Most enterprise use case queries can be supported by utilizing a combination of these two actions. We also keep the system modular to support additional actions in the future.
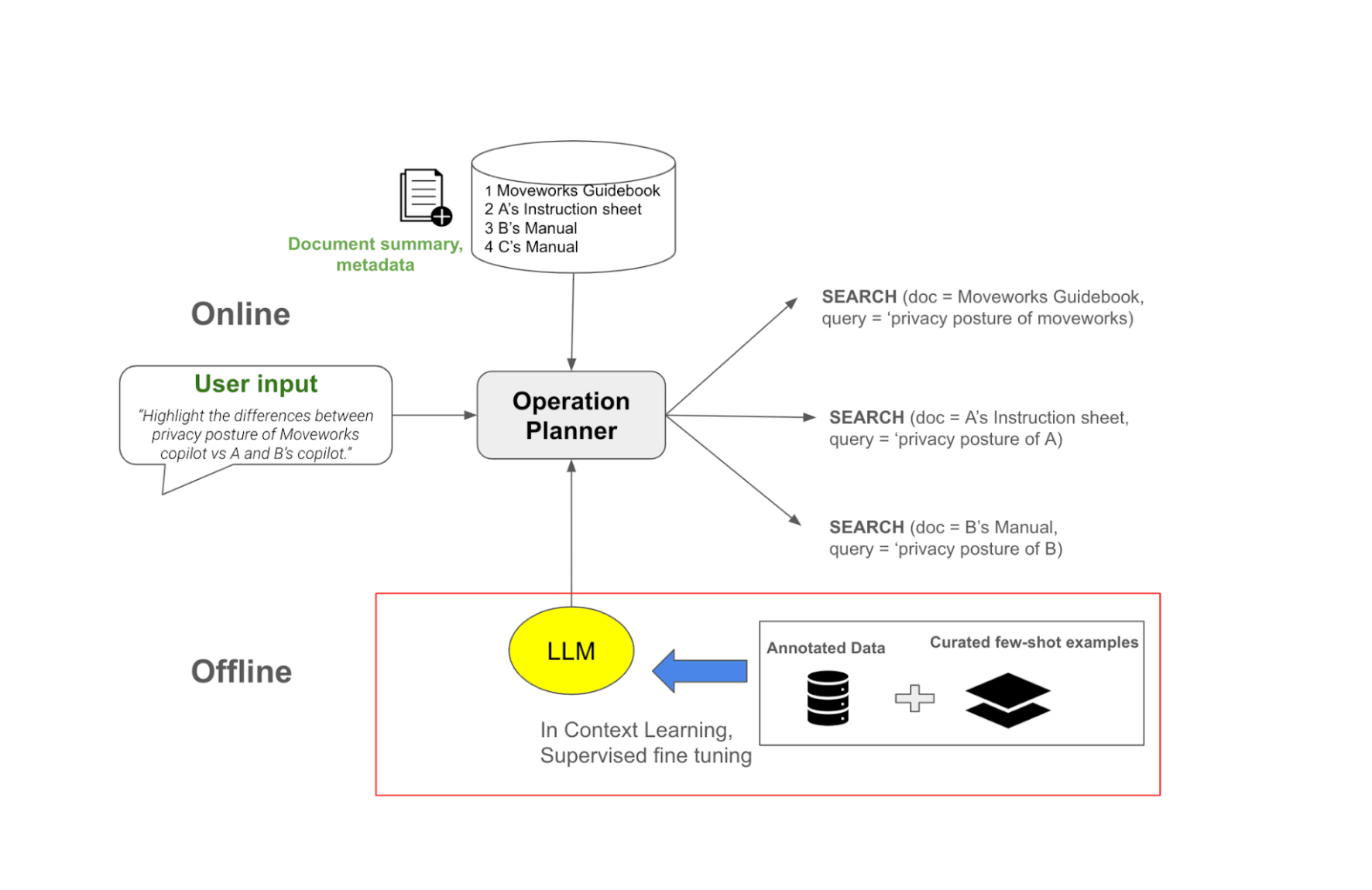 Figure: Illustration of how the operation planner works
Figure: Illustration of how the operation planner works
Action 1: SEARCH
This action indicates the need to search over a document to retrieve snippets. It is primarily used for queries needing to dive into information from a certain portion of a document. It has two parameters
Search query
The document for which the query will run.
In our query above, users have access to documents from Moveworks and its competitors. This scenario would involve three SEARCH operations. The Reasoning Engine limits the search space to generate precise responses. While the system had access to four documents, the search space was constrained to three documents. By systematically filtering and focusing on the most relevant information, we can efficiently address complex queries without being overwhelmed by the volume of data.
Action 2: READ
This action indicates that we need to read the entire document instead of attempting to search. It is particularly crucial for addressing summarization-style problems that cannot be solved by a search or RAG approach. For example, when asked to summarize company A's instruction sheet, one would need to read the entire document and understand its complex nuances before writing a summary. Skipping important sections of the sheet could lead to incomplete summaries.
This example illustrates that in certain cases, searching for specific information is not beneficial and can even be counterproductive. Some tasks require a comprehensive understanding of the entire content. Hence, the context for a READ operation is the entire document. We use a sophisticated map-reduce based algorithm to understand the whole document, which will be discussed in the subsequent section.
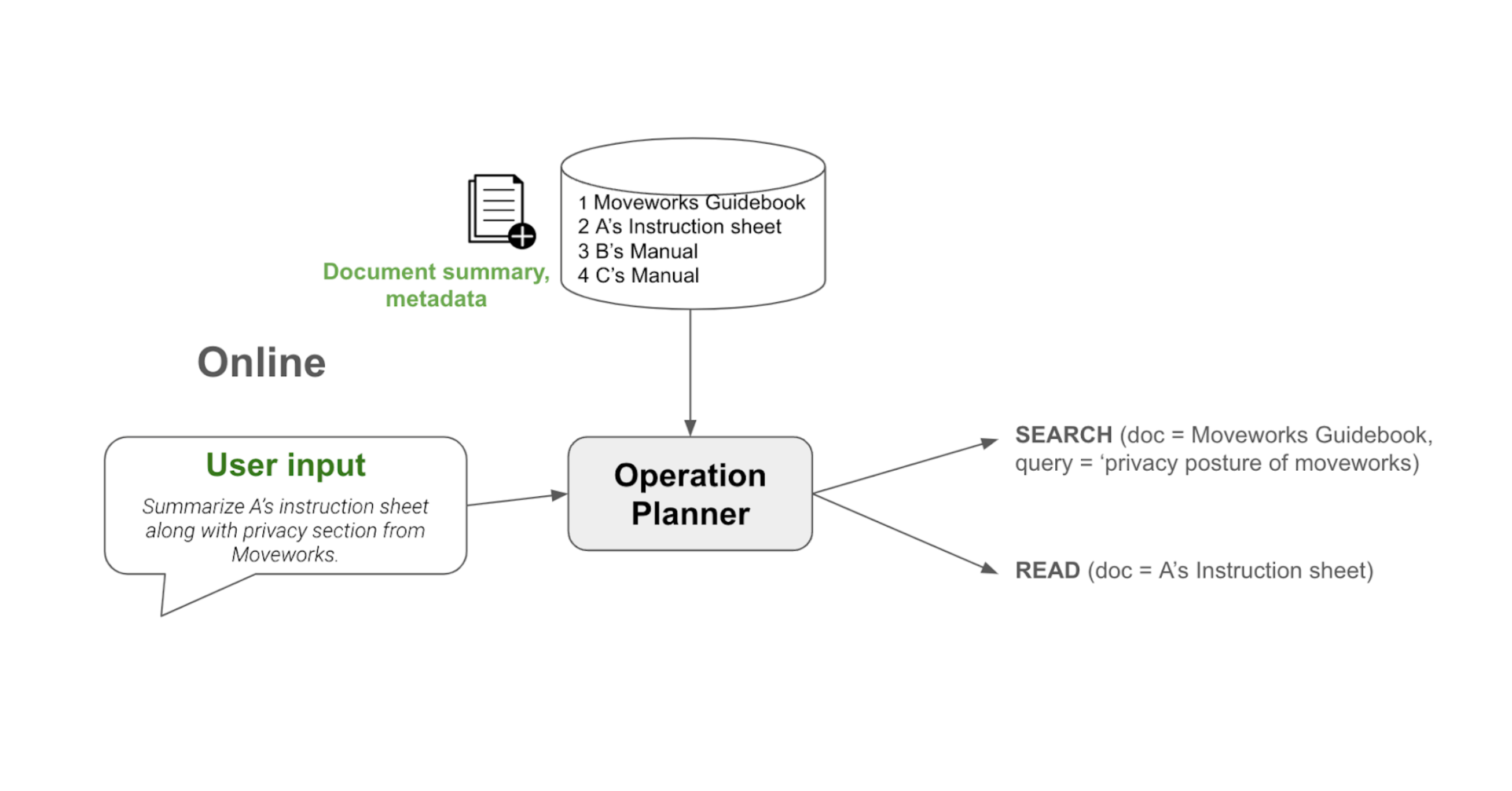 Figure: Another example illustrating Read and Search operations in a single query
Figure: Another example illustrating Read and Search operations in a single query
Tying it all together
The operation planner uses a combination of in-context learning (ICL) and Supervised Fine Tuning (SFT) methods (in progress) to predict the action and corresponding parameters. We have annotated a large set of examples through a mixture of dogfooding and synthetic data generation techniques.
The number of output tokens predicted from this model is going to be small leading to a lower latency. The output is also structured. We use a temperature of 0 to get deterministic outputs using ICL, as the action space is constrained.
Context builder
After operations are predicted, the agent executes each action to build context. Since these actions are independent of each other, they can be executed in parallel to reduce latency.
There are use cases where one action might influence the next set of actions whereas the current architecture only allows for parallel execution. One way of tackling those sets of problems would be to introduce a lightweight model and determine whether the query needs sequential execution. We will only deal with parallelly executable query space in this blog.
The section below would dive into details of how we tackle SEARCH action - one of the key components of any Q & A system.
Executing high precision SEARCH
Search Systems are built to retrieve information from a set of documents. They play a critical role by efficiently delivering relevant results in response to specific queries.
We follow the retrieval + ranking framework to narrow down the chunks of relevant information.
Hybrid search
Embeddings enable more nuanced and context-aware searches by capturing semantic relationships and similarities that go beyond the limitations of keyword match. This allows retrieval systems to understand the underlying meaning and context around queries, returning more relevant results even when exact word matches are not present.
For our agent, we use the following two methods to perform search:
Embeddings-based retrieval of snippets relevant to the query. This has the advantage of higher recall and generalizability.
Keyword-based retrieval of snippets relevant to the query. This has the advantage of higher precision, especially when the query has proper nouns in them that don’t generalize well with embedding models. We use the standard BM25 based keyword search mechanism.
In the section below, we will go deeper into embedding based search.
Diving into embeddings
At Moveworks, we train and finetune our own internal embedding models that understand enterprise jargon. With an established framework to experiment with state-of-the-art embeddings, we are able to push the boundaries of search.
- Model: For Brief Me, we use an MPNet model finetuned using a Bi-encoder approach to understand enterprise context. It is a 100M parameter model that has already shown strong performance on open source benchmarks such as GLUE and SQuAD.
- Training Data: The training data is a mix of human-annotated real-world queries with their corresponding documents and synthetically curated data. Approximately 1 million query-document pairs were used to fine-tune this model.
- Training Method: We use a standard bi-encoder method to train the model. They query and relevant snippets from the document are passed through the Siamese network and cosine similarity is calculated between the embeddings. We use methods such as contrastive and tripless loss to train the network.
- Inference: In Brief Me, whenever a document is uploaded, it is divided into smaller chunks with various levels of granularity. Each chunk is passed through the embedding model to generate an embedding and stored in an OpenSearch index for fast retrieval. An incoming query also gets embedded in the same space, and the most relevant snippets from the document are retrieved using ANN search. We retrieve between 3-5 relevant snippets for each query.
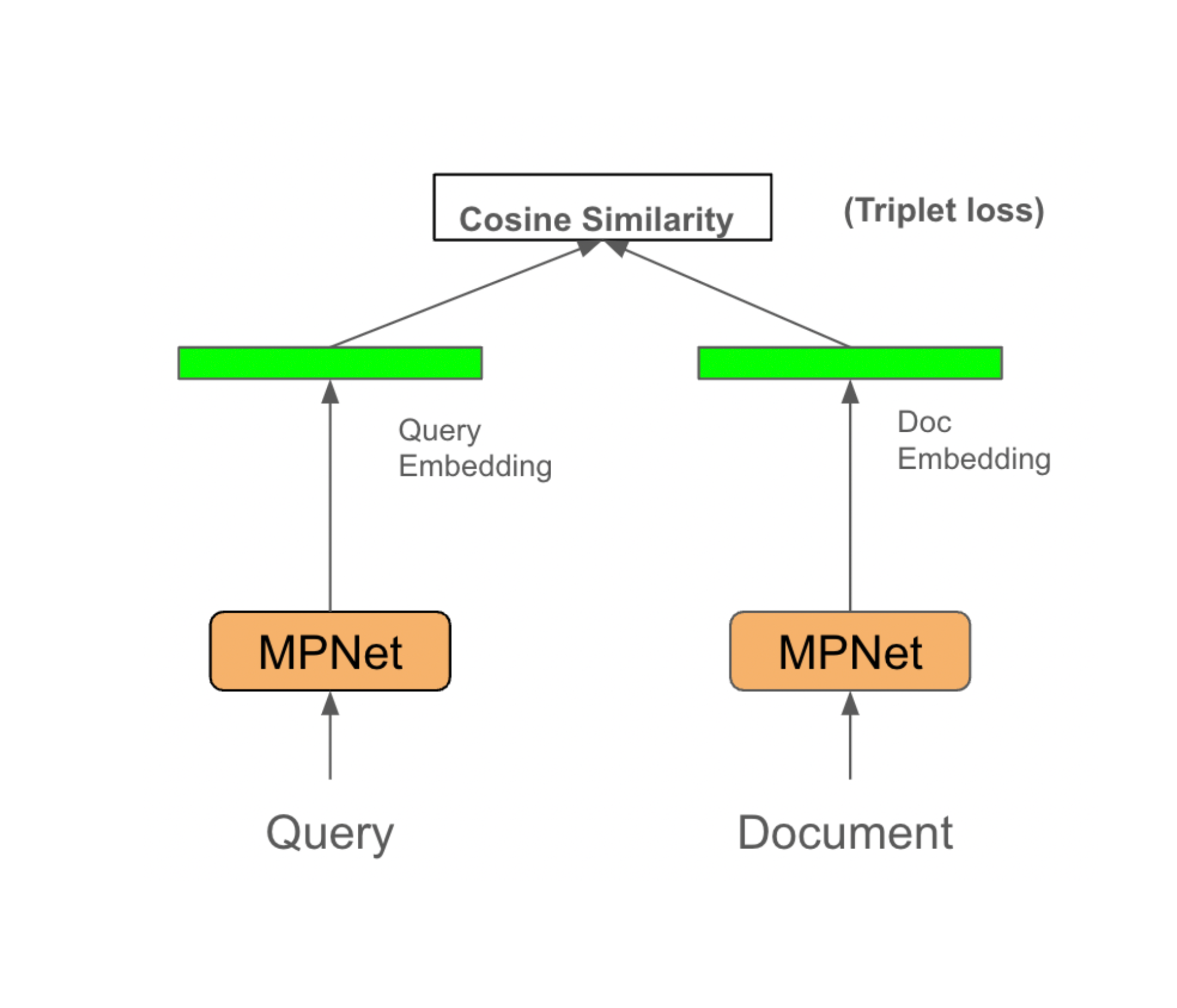 Figure: Training a Bi-encoder Network for embeddings
Figure: Training a Bi-encoder Network for embeddings
Improved contextual awareness through window expansion
After retrieving the top snippets, we introduce a method to augment them through contextual lookups. For each relevant snippet in the document, we employ a dynamic window approach to expand the retrieval context and broaden the receptive field. This technique is particularly useful when answers span multiple pages and a paragraph-level embedding search alone is insufficient to generate comprehensive responses. These heuristics, developed through experimentation, allow us to examine chunks both before and after the relevant ones, enhancing our ability to provide more complete and accurate answers.
For a chunk ID ‘k’ retrieved using ANN, we consider all the chunks from
{ k- cb , k-cb + 1, . . . , k, k + 1 . . . , k+ cf } where, cb and cf are backward and forward expansion constants.
a) We are currently experimenting with semantic window expansion using embeddings to dynamically adjust chunks based on queries and retrieved snippets. This approach helps connect non-neighboring chunks that share a common topic with the most relevant ones, even if they were not initially retrieved. This makes responses more comprehensive and accurate, ensuring that all relevant information is considered.
b) Another approach is contextual chunking performed during the ingestion stage. Each chunk is enriched with information about relevant chunks and associated metadata. This process aims to improve latency.
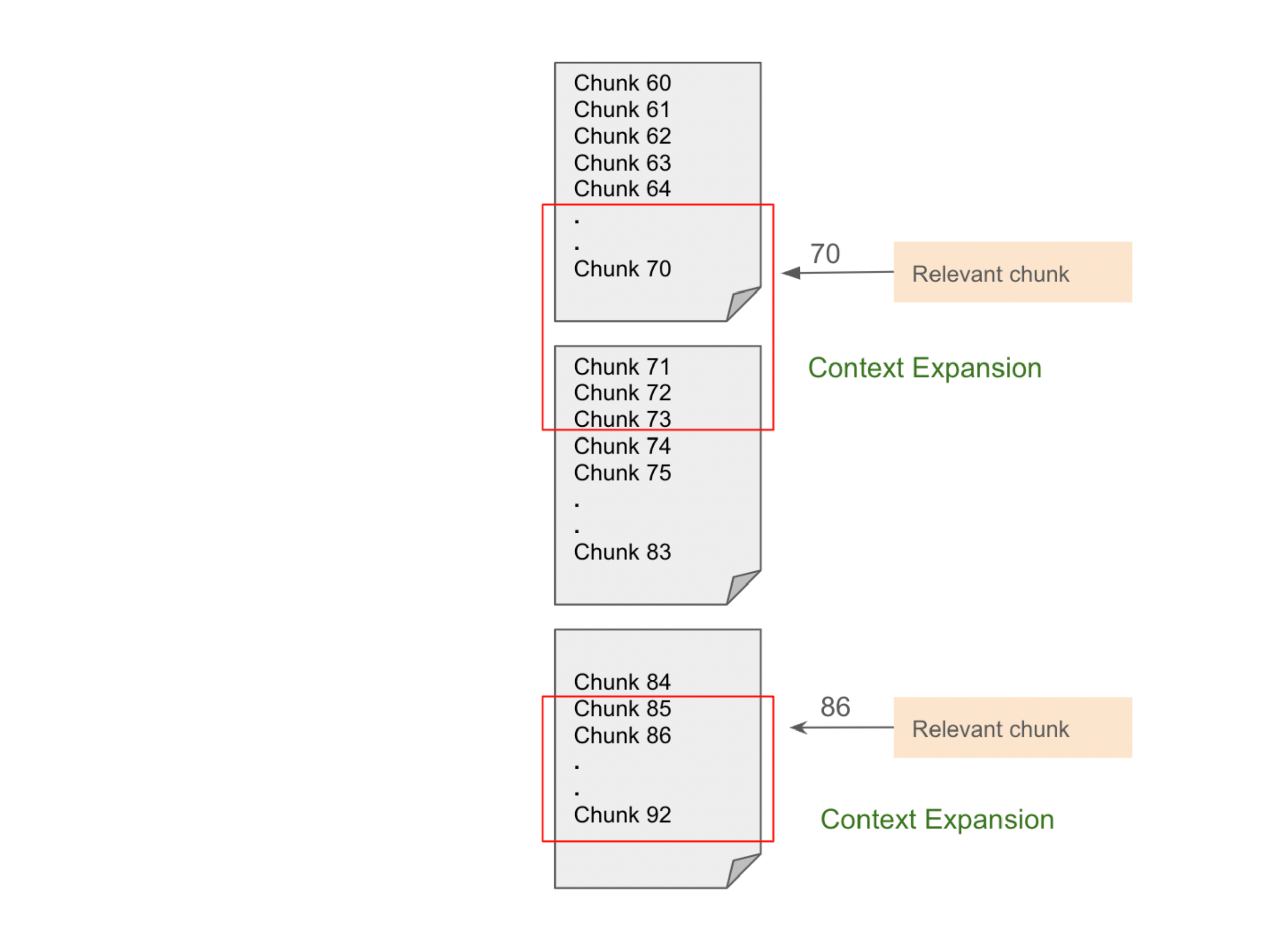 Figure: Illustration of how contextual expansion is conducted
Figure: Illustration of how contextual expansion is conducted
Chunk filtering and ranking
While retrieval casts a wide net to gather potentially relevant results, it is not sufficient in eliminating noise. Ranking is crucial for organizing and curtailing unnecessary information. Ranking algorithms assess the relevance, quality, and importance of retrieved items, ensuring that the most valuable information is prioritized.
We have implemented steps to reorder and filter out noisy snippets, with scope for extensive feature engineering to improve the system:
Filter out retrieved chunks that don't exceed an empirically determined threshold. This threshold has been set based on evaluation metrics and analysis of the precision-recall curve of retrieved results.
Deduplicate chunks after context expansion is done through dynamic window approach.
Rank the chunks using sophisticated feature engineering and filter out chunks based on different ranking scores. Building ranking features is an active area of focus for us and is reused across multiple systems. We will not delve into the details in this blog.
Output generation
After compiling all the relevant context, this component generates the final output response.
Map-reduce based parallel generation
Current language models struggle to effectively utilize information from long input contexts. Performance is typically highest when relevant information appears at the beginning or end of the input context (or prompt), and significantly degrades when models must access pertinent information in the middle of long contexts, even for models explicitly designed for long contexts. Additionally, longer inputs lead to higher latency. For lengthy summaries, there's no guarantee that your content would fit within the context limits.
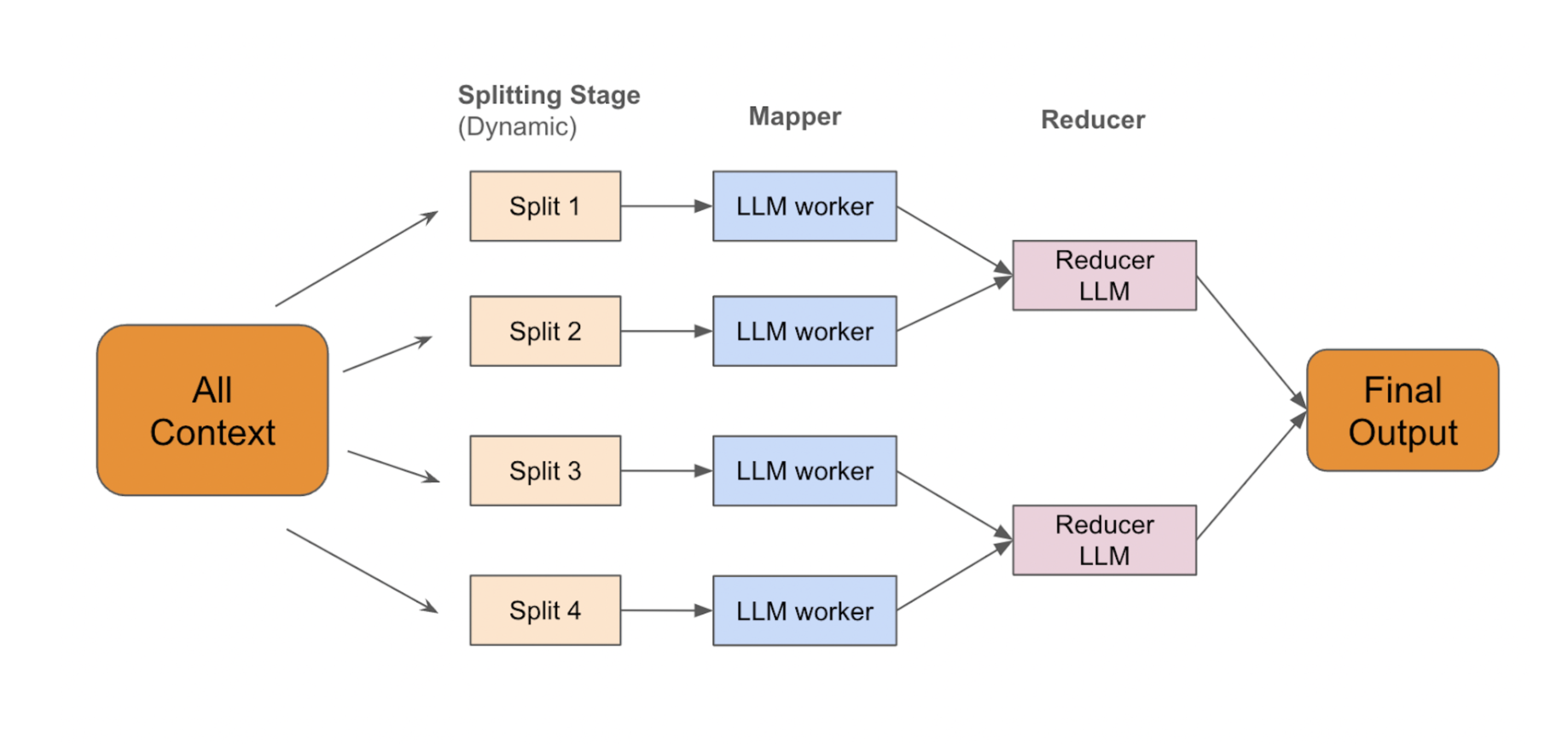
To address these challenges, we introduced a novel map-reduce based algorithm to process contextual data. Here are the steps:
Splitter: The splitter function takes the entire contextual data gathered from previous steps (SEARCH or READ) and dynamically breaks it down into smaller chunks, adhering to token limits, compute capacities, and performance guarantees.
Mapper: The splits are then passed to an LLM worker to generate intermediate outputs. The LLM worker also has access to user query, predicted operations (SEARCH or READ), and metadata from the document store (e.g: document descriptions) to generate grounded and relevant outputs. It also aids in following user instructions more clearly by passing the original query alongside the rewritten query. Empirical studies showed that omitting the original query reduces the instruction-following ability of LLMs due to information loss through various rewrites.
Reducer: These intermediate results are passed to the REDUCE function, which aggregates and combines the data to produce the final output. This step uses a specifically tuned prompting library designed to combine information from various sources. For example, we maintain distinctions between information sourced from PPTs versus DOCs.
MapReduce's ability to scale horizontally makes it an essential tool for answering complex queries that require reasoning over extremely long contexts without sacrificing quality.
Additional engineering enhancements to improve the latency, scalability, and reliability of the system were made and tested using evaluations:
- We introduced truncated Map-reduce to limit the number of possible splits the system can make. To avoid overburdening worker nodes, we stop accepting splits once we reach a maximum limit. Strategies to achieve this include:
- Naively stopping once the limit is reached, potentially skipping the last few chunks. This can lead to information loss from tail chunks.
- Selectively skipping chunks if they are very similar, enhancing our receptive field by including wider chunk windows in each split.
- In the splitter stage, we use a streaming splitter to yield splits as they are generated in sequence. We don't wait for all splits before processing, saving time and reducing the burden on workers. This allows for the possibility that a certain worker may be freed while the last split is still being generated.
- We designed the reducer stage to keep references to the original splits, even though it only has access to the intermediate outputs. This aids in generating grounded attributions to the source chunks in the output. We will discuss citations in the next section.
Citations
Where possible, the agent must provide accurate citations for claims made in its response. A claim in the agent's response must not link to an unrelated snippet or document chunk that does not substantiate that claim.
Most existing tools either don't provide citations or only offer citations at the document level. Brief Me, however, is capable of providing citations at the paragraph level, enabling users to place greater trust in the generated responses. We employ a combination of LLM and heuristic-based methods, such as n-gram matching, to attribute each output sentence with verifiable links to specific paragraphs in the corresponding documents.
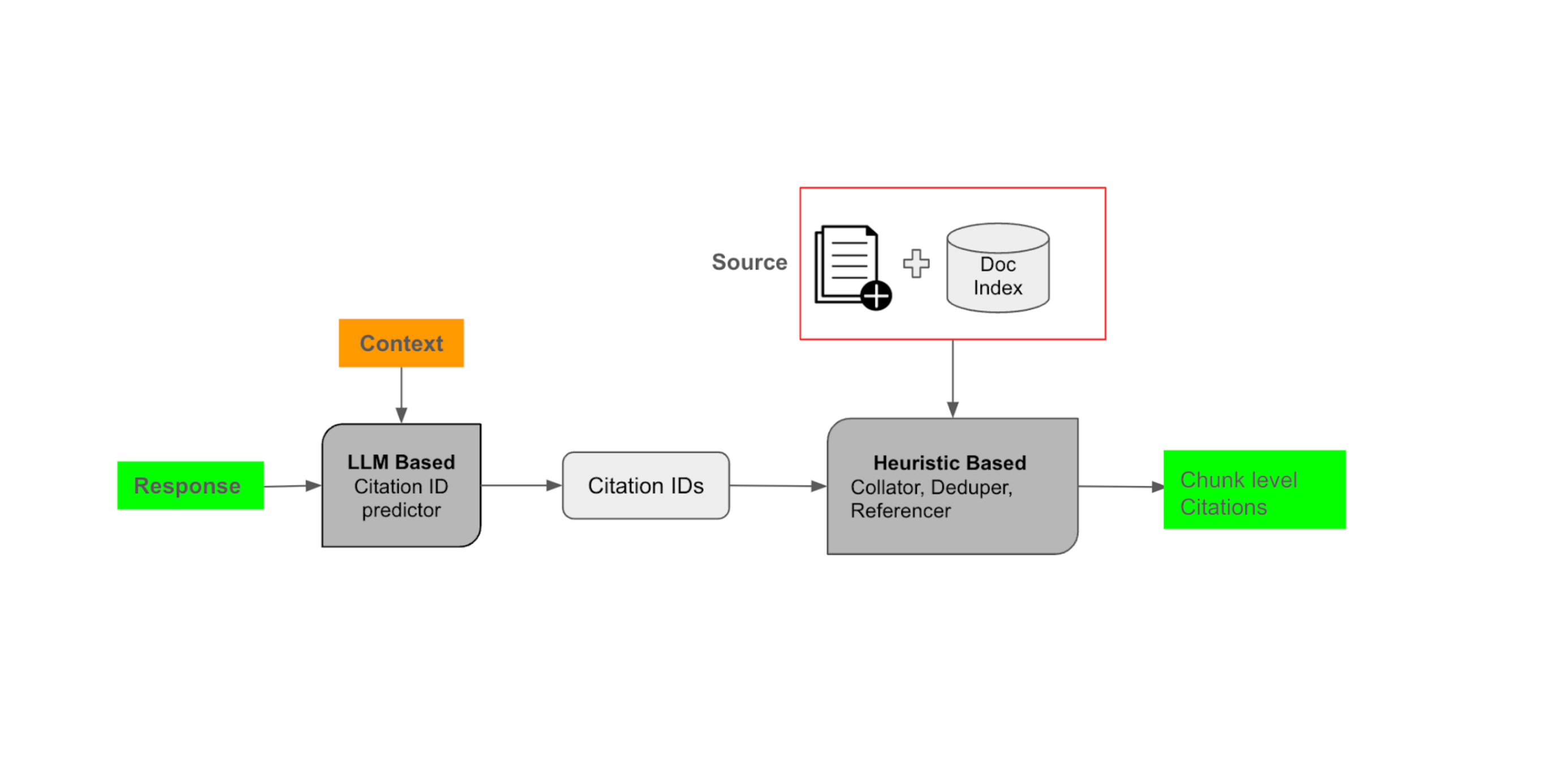 Figure: Illustration of the core citation system
Figure: Illustration of the core citation system
A model is used to predict the list of citation IDs based on the output response and relevant context. The citations need to be: a) complete - not omitting relevant attributions, and b) appropriately sparse - we don't want to overwhelm users with hundreds of citations for a single paragraph.
Once the citation IDs are generated, we employ a heuristic-based system to further enhance citation quality and link them to the source documents:
Collator: Multiple collate operations are performed. One such collator combines consecutive citation chunk IDs. e.g: [10][8-13][9-12] -> [8-13]
Deduper: It's possible to get similar citation IDs for a series of response sentences. This step helps identify the right granularity for displaying citations using heuristics, custom rules, and regex, and then deduplicates the IDs.
Referencer: We map the citation IDs to actual chunks from the document while ensuring granularity, sparsity, and completeness.
Evaluation framework
A complex agent such as Brief Me can have multiple points of failure which warrants an extensive evaluation framework to measure the efficacy of individual components for both single turn queries and multi-turn session performance.
Dataset
The evaluation was conducted on a set of 2,200 query-response pairs based on real usage data. The uploaded sources came from a variety of domains, including research papers, financial reports, security documents, HR policies, competitive intelligence, sales pitches, and more. Usage data was logged, monitored, and sent to trained human annotators for review.
Each task was evaluated on a 3-point scale, where "Yes" corresponds to 1, "Somewhat" corresponds to 2, and "No" corresponds to 3.
Metrics
There are 10 different parameters to evaluate a query turn and we are working on a session based evaluation strategy. We evaluate through a) human labellers with efforts underway to use b) sophisticated LLM graders increasing our ability to annotate larger sets. The section below will list down some sample evaluation metrics
Operation planner:
- Action accuracy: It measures how accurate the action predictions are.
- Resource prediction accuracy: Measures the correctness of chosen resources (docs)
- Search query quality: The huge query must be broken down into subqueries for ease of processing for SEARCH use cases. This field is absent for READ queries.
Table: Metrics on sample tasks. Refer to the dataset section for details on sample size and annotation.
Yes | Somewhat | No | |
Correct Actions | 97.24 | 0.00 | 2.76 |
Correct Resources | 97.35 | 0.00 | 2.65 |
Search Query Quality | 93.80 | 5.20 | 1.94 |
Completeness | 97.98 | 0.00 | 2.10 |
Groundedness | 89.21 | 6.20 | 4.71 |
Retrieval Precision @3 | 65.11 | 26.74 | 9.50 |
Search metrics
- Retrieval precision@k. Measures relevance of retrieved information. Retrieval precision is also useful when the goal is to minimize hallucination.
- Retrieval recall@k: Indicates proportion of relevant documents retrieved. This is the most useful relevance metric for retrieval. E.g. a recall of 0.5 indicates that half of the relevant documents failed to be retrieved.
Output quality
- Completeness: Assesses whether the agent's response appears to be a reasonable answer to the user query in the context of the conversation. Note that this does not address the correctness of the assistant's response.
- Groundedness: Evaluates whether the generated content is faithful to the retrieved content and to any information provided in the user query.
- Citation Correctness: Measures whether the output citations have proper attributions to actual document sources.
Brief Me: The faster way to discover key insights
Throughout this article, we’ve discussed the capabilities of the Brief Me system, a real-time content generation tool that utilizes various sources such as documents, URLs, and intranet links to generate content. We’ve explored how this system is designed to handle a wide range of tasks from simple Q&A style inquiries to more complex content generation tasks like summary, analysis, comparison, and insight creation, as well as its content ingestion and content generation processes.
We’ve also discussed the many practical applications of Brief Me in a business context, and how without Brief Me, this process would likely involve manual searching, reading, processing, and developing a viewpoint to position, all of which would be comparatively more time-consuming and less efficient.
For all these reasons and more, we consider Brief Me to be a versatile tool that transforms and leverages information into a wide range of applicable uses. It not only simplifies the process of content generation but also ensures that the generated content is accurate, grounded, and verifiable. Whether it's answering simple questions or generating complex content, Brief Me is able to handle it, helping to make it an invaluable tool in today's fast-paced, information-driven world.
Need a faster way to extract key insights from documents? Learn more about Brief Me or demo it for yourself.
Table of contents


